개발사 스캐터랩은 15일 일요신문과의 통화에서 “이루다 개발 데이터베이스에 텍스트앳의 대화 데이터도 포함된 것이 맞다”고 밝혔다. 텍스트앳은 스캐터랩에서 2013년 출시한 감정분석 서비스로 카카오톡 대화를 분석해 상대방의 감정을 읽어주는 서비스다. 사용자들 사이에선 연애의 과학 초기 버전으로 이해되고 있다.
최근 이루다 개인정보 관리 부실 논란이 커지면서 사용자들 사이에서 텍스트앳의 카카오톡 대화도 AI 학습에 활용된 것이 아니냐는 의혹이 커지고 있었다. 스캐터랩은 “이루다를 개발하는 과정에서 연애의 과학으로 수집한 100억 건의 대화 데이터를 활용한 바 있다”고 밝혔으나 지금까지 텍스트앳은 언급하지 않았다.

2019년 5월~6월 스캐터랩이 네이버에서 한 강연 자료. 왼쪽이 텍스트앳, 오른쪽이 연애의 과학 아이콘이다. 사진=스캐터랩 PPT
그러나 일요신문 취재 결과, 이루다 개발 데이터베이스에는 텍스트앳의 대화 데이터도 쓰인 것으로 확인됐다. 스캐터랩은 2019년 5월 네이버에서 진행한 한 강연에서 일상대화 AI 핑퐁 개발 과정을 설명하면서 이에 대한 데이터로 연애의 과학과 텍스트앳의 유저 대화데이터 100억 건이 쓰였다고 밝혔다.
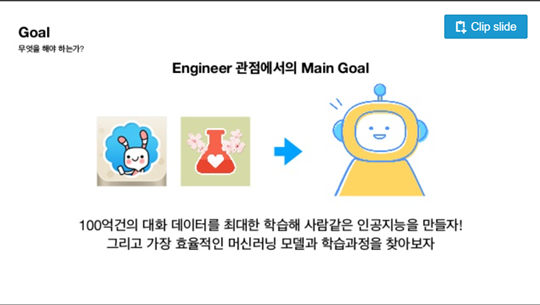
2019년 5월~6월 스캐터랩이 네이버에서 한 강연 자료. 현재 강연 동영상은 삭제되었다. 사진=스캐터랩 PPT
당시 발표된 자료를 살펴보면 100억 건의 유저 대화 데이터는 연애의 과학과 텍스트앳 아이콘이 함께 제시됐다. 그러면서 연애를 위한 인공지능이라는 설명도 언급됐다. 두 앱을 통해 유저 대화 데이터를 얻었다는 내용으로 강연이 진행됐음을 유추해볼 수 있다. 개발자는 100억 건의 대화 데이터를 최대한 학습해 사람 같은 인공지능을 만드는 것이 목표라고 했다. 이 결과 만들어진 것이 현재의 대화형 챗봇인 ‘핑퐁’이다. 이루다는 핑퐁의 데이터베이스를 통해 프리트레이닝 단계를 거쳤다. 다시 말해 핑퐁은 이루다의 학습 베이스가 된 것이다.
2019년 6월 네이버 동영상에 업로드되어 있던 이 강연 영상은 현재 삭제되어 확인할 수 없다. 다만 다른 강연들은 여전히 재생이 가능하다. 이에 대해 스캐터랩 관계자는 “본사 측에서 영상 삭제를 부탁했는지 확인해 봐야 한다”고 말했다.
한편 스캐터랩 측은 1월 14일 오후 텍스트앳 대화 데이터 활용에 대한 일요신문 질의서를 받고 15일 오전 보도 자료를 통해 대화 모델 폐기를 결정하겠다고 밝혔다. 스캐터랩 관계자는 15일 일요신문과의 통화에서 “이루다의 학습 데이터에 연애의 과학과 텍스트앳 대화 데이터가 사용된 것이 맞다”며 “이용자들의 불안감을 고려해 이번 인공지능 이루다의 DB 전량 및 딥러닝 대화 모델을 폐기하기로 했다”고 밝혔다.
스캐터랩은 현재 한국인터넷진흥원(KISA) 및 개인정보보호위원회의 조사를 받고 있으며, 조사가 종료되는 즉시 이루다 DB와 딥러닝 대화 모델의 폐기를 진행한다는 방침이다. 기존 연애의 과학과 텍스트앳에서 이용자의 동의를 받고 수집되었던 기존 데이터는 데이터 활용을 원하지 않는 이용자로부터 신청을 받은 뒤, 해당 이용자의 데이터를 모두 삭제할 예정이다. 또한 향후 딥러닝 대화 모델에도 이용되지 않는다.
한편 스캐터랩은 개인정보 유출 의혹을 받고 있다. 개발사가 이루다 개발을 위한 테스트 샘플을 깃허브에 올리면서 카톡 데이터 100건이 공개된 까닭이다. 데이터 100건에 담겨 있는 카톡 대화량은 1700건에 달한다. 그런데 이 카톡 대화 데이터에는 이름 20여 건이 포함돼 있으며, 대화를 나누는 사람들의 관계가 상당수 드러나 있어 논란이 됐다. 다만 이 정보가 개인정보에 해당하는지는 향후 조사를 통해 밝혀질 예정이다.
최희주 기자 hjoo@ilyo.co.kr










